Textslam学习记录
textslam将文字中的语义信息引入到slam系统中,使用文字的语义信息来引导视觉里程计中的track过程和回环过程。
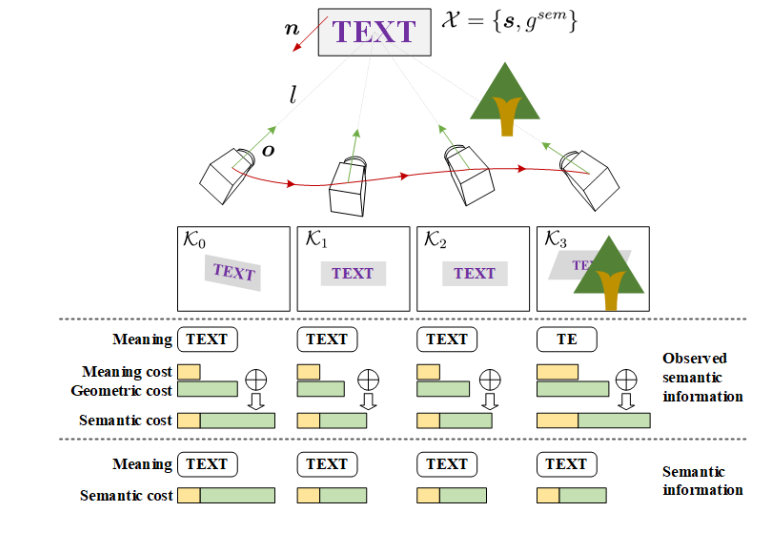
几何模型和观测
textslam将每一块文字视作一个平面,这里不可避免的牵涉到单应矩阵,考虑到地图点逆深度参数化以及(n,d)表示平面的过参数化问题,文章修改了一下参数的形式。
DSO中使用仿射模型来进行光度一致性矫正,并且将仿射参数加入到BA框架中。textslam中使用零均值归一化互相关来进行光度一致性矫正。

语义信息管理
语义信息由两部分组成,一个是文字语义也就是字符串(后面进行单词匹配的时候用到),另一个是语义损失(进行语义信息更新的时候用到)。语义损失又由两部分组成,Meaning cost和geometric cost两部分,前者是使用AttentionOCR预测得到的置信度范围在[0,1],geometric cost是几何损失,由文字平面与光心的距离和角度组成。
更新的时候一直选择语义损失最小的语义信息组。
系统流程图
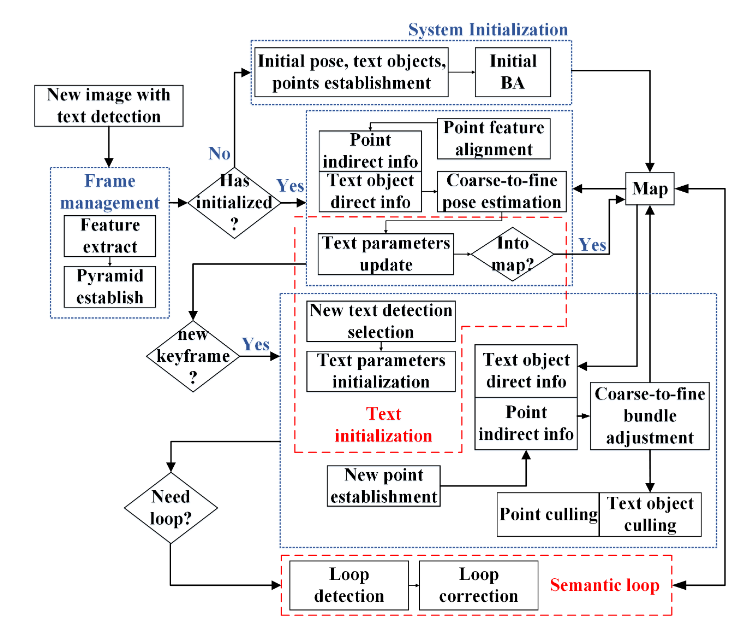
文本对象初始化
由两帧关键帧进行初始化,首先对前一帧进行FAST关键点检测,然后使用KLT光流得到FAST关键点在另一帧中的位置,解方程可以得到文本对象的参数。
之后的Track的cost function是几何误差加上光度误差。(据作者所说,这里的几何误差是文本对象左上左下右上右下四个点3D-2D的投影误差)。光度误差没有使用文本对象范围内所有的像素点,而是使用FAST关键点作为代表性像素点。
BA优化的cost function和Track的一样。
使用场景文本对象进行闭环检测
考虑到其他的SLAM系统都是使用关键点组成的词典进行回环检测,作者这里直接使用文字语义组成的真实词袋来进行回环。文本误差函数如下:
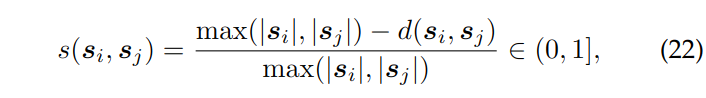
|s|代表文字的长度,d()是Levenshtein distance,也就是将一个字符串变换到另一个字符串所需要进行的删除插入替换的操作次数,跟汉明距离有点像。
可以很容易得到回环候选帧。然后使用匹配文本区域内的关键点匹配进行位姿优化。